3.1 Simple unpivoting
The behead() function takes one level of headers from a pivot table and makes
it part of the data. Think of it like tidyr::gather(), except that it works
when there is more than one row of headers (or more than one column of
row-headers), and it only works on tables that have first come through
as_cells() or tidyxl::xlsx_cells().
3.1.1 Two clear rows of text column headers, left-aligned
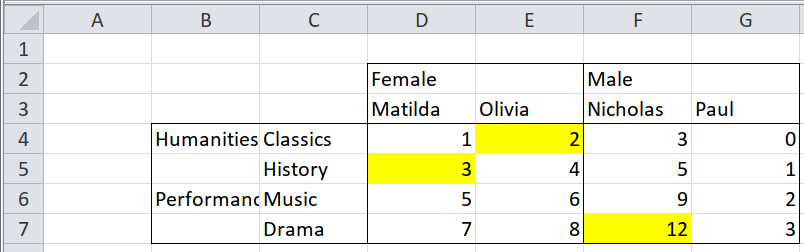
Here we have a pivot table with two rows of column headers. The first row of
headers is left-aligned, so "Female" applies to the first two columns of data,
and "Male" applies to the next two. The second row of headers has a header in
every column.
path <- system.file("extdata", "worked-examples.xlsx", package = "unpivotr")
all_cells <-
xlsx_cells(path, sheets = "pivot-annotations") %>%
dplyr::filter(col >= 4, !is_blank) %>% # Ignore the row headers in this example
select(row, col, data_type, character, numeric)
all_cells## # A tibble: 22 x 5
## row col data_type character numeric
## <int> <int> <chr> <chr> <dbl>
## 1 2 4 character Female NA
## 2 2 6 character Male NA
## 3 3 4 character Matilda NA
## 4 3 5 character Olivia NA
## 5 3 6 character Nicholas NA
## 6 3 7 character Paul NA
## 7 4 4 numeric <NA> 1
## 8 4 5 numeric <NA> 2
## 9 4 6 numeric <NA> 3
## 10 4 7 numeric <NA> 0
## # … with 12 more rowsThe behead() function takes the ‘melted’ output of as_cells(),
tidyxl::xlsx_cells(), or a previous behead(), and three more arguments to
specify how the header cells relate to the data cells.
The outermost header is the top row, "Female" NA "Male" NA. The "Female"
and "Male" headers are up-and-to-the-left-of the data cells. We express
this as "up-left". We also give the headers a name, sex, and say which
column of all_cells contains the value of the header cells – it’s usually the
character column.
## # A tibble: 20 x 6
## row col data_type character numeric sex
## <int> <int> <chr> <chr> <dbl> <chr>
## 1 3 4 character Matilda NA Female
## 2 3 5 character Olivia NA Female
## 3 4 4 numeric <NA> 1 Female
## 4 4 5 numeric <NA> 2 Female
## 5 5 4 numeric <NA> 3 Female
## 6 5 5 numeric <NA> 4 Female
## 7 6 4 numeric <NA> 5 Female
## 8 6 5 numeric <NA> 6 Female
## 9 7 4 numeric <NA> 7 Female
## 10 7 5 numeric <NA> 8 Female
## 11 3 6 character Nicholas NA Male
## 12 3 7 character Paul NA Male
## 13 4 6 numeric <NA> 3 Male
## 14 4 7 numeric <NA> 0 Male
## 15 5 6 numeric <NA> 5 Male
## 16 5 7 numeric <NA> 1 Male
## 17 6 6 numeric <NA> 9 Male
## 18 6 7 numeric <NA> 2 Male
## 19 7 6 numeric <NA> 12 Male
## 20 7 7 numeric <NA> 3 MaleThat did half the job. The value 2 in row 4 column 5 is indeed a score of a
female. But the value "matilda" in row 3 column 4 isn’t a population – it’s
another header. The next step is to strip that second level of column headers.
This time, the direction is "up", because the headers are directly
up from the associated data cells, and we call it name, because it represents
names of people.
## # A tibble: 16 x 7
## row col data_type character numeric sex name
## <int> <int> <chr> <chr> <dbl> <chr> <chr>
## 1 4 4 numeric <NA> 1 Female Matilda
## 2 4 5 numeric <NA> 2 Female Olivia
## 3 5 4 numeric <NA> 3 Female Matilda
## 4 5 5 numeric <NA> 4 Female Olivia
## 5 6 4 numeric <NA> 5 Female Matilda
## 6 6 5 numeric <NA> 6 Female Olivia
## 7 7 4 numeric <NA> 7 Female Matilda
## 8 7 5 numeric <NA> 8 Female Olivia
## 9 4 6 numeric <NA> 3 Male Nicholas
## 10 4 7 numeric <NA> 0 Male Paul
## 11 5 6 numeric <NA> 5 Male Nicholas
## 12 5 7 numeric <NA> 1 Male Paul
## 13 6 6 numeric <NA> 9 Male Nicholas
## 14 6 7 numeric <NA> 2 Male Paul
## 15 7 6 numeric <NA> 12 Male Nicholas
## 16 7 7 numeric <NA> 3 Male PaulA final step is a normal clean-up. We drop the row, col and character
columns, and we rename the numeric column to score, which is what it
represents.
all_cells %>%
behead("up-left", sex) %>%
behead("up", `name`) %>%
select(score = numeric, sex, `name`)## # A tibble: 16 x 3
## score sex name
## <dbl> <chr> <chr>
## 1 1 Female Matilda
## 2 2 Female Olivia
## 3 3 Female Matilda
## 4 4 Female Olivia
## 5 5 Female Matilda
## 6 6 Female Olivia
## 7 7 Female Matilda
## 8 8 Female Olivia
## 9 3 Male Nicholas
## 10 0 Male Paul
## 11 5 Male Nicholas
## 12 1 Male Paul
## 13 9 Male Nicholas
## 14 2 Male Paul
## 15 12 Male Nicholas
## 16 3 Male Paul3.1.2 Two clear rows and columns of text headers, top-aligned and left-aligned
There are no new techniques are used, just more directions: "left" for headers
directly to the left of the data cells, and "left-up" for headers left-then-up
from the data cells.
path <- system.file("extdata", "worked-examples.xlsx", package = "unpivotr")
all_cells <-
xlsx_cells(path, sheets = "pivot-annotations") %>%
dplyr::filter(!is_blank) %>%
select(row, col, data_type, character, numeric) %>%
print()## # A tibble: 28 x 5
## row col data_type character numeric
## <int> <int> <chr> <chr> <dbl>
## 1 2 4 character Female NA
## 2 2 6 character Male NA
## 3 3 4 character Matilda NA
## 4 3 5 character Olivia NA
## 5 3 6 character Nicholas NA
## 6 3 7 character Paul NA
## 7 4 2 character Humanities NA
## 8 4 3 character Classics NA
## 9 4 4 numeric <NA> 1
## 10 4 5 numeric <NA> 2
## # … with 18 more rowsall_cells %>%
behead("up-left", sex) %>% # As before
behead("up", `name`) %>% # As before
behead("left-up", field) %>% # Left-and-above
behead("left", subject) %>% # Directly left
rename(score = numeric) %>%
select(-row, -col, -character)## # A tibble: 16 x 6
## data_type score sex name field subject
## <chr> <dbl> <chr> <chr> <chr> <chr>
## 1 numeric 1 Female Matilda Humanities Classics
## 2 numeric 2 Female Olivia Humanities Classics
## 3 numeric 3 Female Matilda Humanities History
## 4 numeric 4 Female Olivia Humanities History
## 5 numeric 3 Male Nicholas Humanities Classics
## 6 numeric 0 Male Paul Humanities Classics
## 7 numeric 5 Male Nicholas Humanities History
## 8 numeric 1 Male Paul Humanities History
## 9 numeric 5 Female Matilda Performance Music
## 10 numeric 6 Female Olivia Performance Music
## 11 numeric 7 Female Matilda Performance Drama
## 12 numeric 8 Female Olivia Performance Drama
## 13 numeric 9 Male Nicholas Performance Music
## 14 numeric 2 Male Paul Performance Music
## 15 numeric 12 Male Nicholas Performance Drama
## 16 numeric 3 Male Paul Performance Drama3.1.3 Multiple rows or columns of headers, with meaningful formatting
This is a combination of the previous section with meaningfully formatted rows. The section meaninfully formatted cells doesn’t work here, because the unpivoting of multiple rows/columns of headers complicates the relationship between the data and the formatting.
- Unpivot the multiple rows/columns of headers, as above, but keep the
rowandcolof each data cell. - Collect the
row,coland formatting of each data cell. - Join the data to the formatting by the
rowandcol.
path <- system.file("extdata", "worked-examples.xlsx", package = "unpivotr")
all_cells <-
xlsx_cells(path, sheets = "pivot-annotations") %>%
dplyr::filter(!is_blank) %>%
select(row, col, data_type, character, numeric) %>%
print()## # A tibble: 28 x 5
## row col data_type character numeric
## <int> <int> <chr> <chr> <dbl>
## 1 2 4 character Female NA
## 2 2 6 character Male NA
## 3 3 4 character Matilda NA
## 4 3 5 character Olivia NA
## 5 3 6 character Nicholas NA
## 6 3 7 character Paul NA
## 7 4 2 character Humanities NA
## 8 4 3 character Classics NA
## 9 4 4 numeric <NA> 1
## 10 4 5 numeric <NA> 2
## # … with 18 more rowsunpivoted <-
all_cells %>%
behead("up-left", sex) %>% # As before
behead("up", `name`) %>% # As before
behead("left-up", field) %>% # Left-and-above
behead("left", subject) %>% # Directly left
rename(score = numeric) %>%
select(-character) # Retain the row and col for now
unpivoted## # A tibble: 16 x 8
## row col data_type score sex name field subject
## <int> <int> <chr> <dbl> <chr> <chr> <chr> <chr>
## 1 4 4 numeric 1 Female Matilda Humanities Classics
## 2 4 5 numeric 2 Female Olivia Humanities Classics
## 3 5 4 numeric 3 Female Matilda Humanities History
## 4 5 5 numeric 4 Female Olivia Humanities History
## 5 4 6 numeric 3 Male Nicholas Humanities Classics
## 6 4 7 numeric 0 Male Paul Humanities Classics
## 7 5 6 numeric 5 Male Nicholas Humanities History
## 8 5 7 numeric 1 Male Paul Humanities History
## 9 6 4 numeric 5 Female Matilda Performance Music
## 10 6 5 numeric 6 Female Olivia Performance Music
## 11 7 4 numeric 7 Female Matilda Performance Drama
## 12 7 5 numeric 8 Female Olivia Performance Drama
## 13 6 6 numeric 9 Male Nicholas Performance Music
## 14 6 7 numeric 2 Male Paul Performance Music
## 15 7 6 numeric 12 Male Nicholas Performance Drama
## 16 7 7 numeric 3 Male Paul Performance Drama# `formats` is a pallette of fill colours that can be indexed by the
# `local_format_id` of a given cell to get the fill colour of that cell
fill_colours <- xlsx_formats(path)$local$fill$patternFill$fgColor$rgb
fill_colours## [1] NA NA NA NA NA NA NA NA
## [9] "FFFFFF00" "FF92D050" "FFFFFF00" NA NA "FFFFFF00" NA NA
## [17] NA NA NA NA NA "FFFFFF00" "FFFFFF00" NA
## [25] NA "FFFFFF00" NA NA NA NA NA NA
## [33] NA NA NA NA NA NA NA NA
## [41] NA NA NA NA NA NA NA NA
## [49] NA NA NA NA NA NA NA NA
## [57] "FFFFC7CE" NA NA# Import all the cells, filter out the header row, filter for the first column,
# and create a new column `approximate` based on the fill colours, by looking up
# the local_format_id of each cell in the `formats` pallette.
annotations <-
xlsx_cells(path, sheets = "pivot-annotations") %>%
dplyr::filter(row >= 4, col >= 4) %>% # Omit the headers
mutate(fill_colour = fill_colours[local_format_id]) %>%
select(row, col, fill_colour)
annotations## # A tibble: 16 x 3
## row col fill_colour
## <int> <int> <chr>
## 1 4 4 <NA>
## 2 4 5 FFFFFF00
## 3 4 6 <NA>
## 4 4 7 <NA>
## 5 5 4 FFFFFF00
## 6 5 5 <NA>
## 7 5 6 <NA>
## 8 5 7 <NA>
## 9 6 4 <NA>
## 10 6 5 <NA>
## 11 6 6 <NA>
## 12 6 7 <NA>
## 13 7 4 <NA>
## 14 7 5 <NA>
## 15 7 6 FFFFFF00
## 16 7 7 <NA>## # A tibble: 16 x 7
## data_type score sex name field subject fill_colour
## <chr> <dbl> <chr> <chr> <chr> <chr> <chr>
## 1 numeric 1 Female Matilda Humanities Classics <NA>
## 2 numeric 2 Female Olivia Humanities Classics FFFFFF00
## 3 numeric 3 Female Matilda Humanities History FFFFFF00
## 4 numeric 4 Female Olivia Humanities History <NA>
## 5 numeric 3 Male Nicholas Humanities Classics <NA>
## 6 numeric 0 Male Paul Humanities Classics <NA>
## 7 numeric 5 Male Nicholas Humanities History <NA>
## 8 numeric 1 Male Paul Humanities History <NA>
## 9 numeric 5 Female Matilda Performance Music <NA>
## 10 numeric 6 Female Olivia Performance Music <NA>
## 11 numeric 7 Female Matilda Performance Drama <NA>
## 12 numeric 8 Female Olivia Performance Drama <NA>
## 13 numeric 9 Male Nicholas Performance Music <NA>
## 14 numeric 2 Male Paul Performance Music <NA>
## 15 numeric 12 Male Nicholas Performance Drama FFFFFF00
## 16 numeric 3 Male Paul Performance Drama <NA>3.1.4 Mixed headers and notes in the same row/column, distinguished by formatting
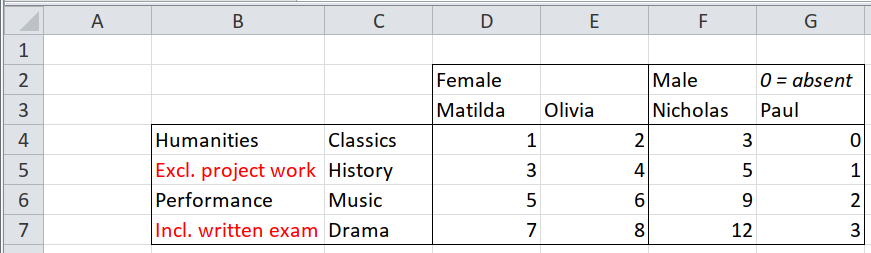
This needs two passes over each row/column that contains a mixture. The first
pass, with behead_if() is to deal with the cells that are headers, and the
second pass, with dplyr::filter() removes the remaining cells that are notes.
The behead_if() function takes predicate functions to choose which cells are
headers.
# only treat bold cells beginning "Country: " as a header
cells %>%
behead_if(formats$local$font$bold[local_format_id], # true for bold cells
str_detect(character, "^Country: "), # true for "Country: ..."
direction = "left-up", # argument must be named
name = "country_name") %>%
dplyr::filter(col != 1L) # discard remaining cellsNote that the direction and name arguments must now be named, because they
follow the ....
After behead_if(), any cells that haven’t been treated as headers will still
exist, so if you want to discard them then use dplyr::filter() on the column
or row number.
In the screenshot above, cells with italic or red text aren’t headers, even though they are in amongst header cells.
First, identify the IDs of formats that have italic or red text.
path <- system.file("extdata", "worked-examples.xlsx", package = "unpivotr")
formats <- xlsx_formats(path)
italic <- formats$local$font$italic
# For 'red' we can either look for the RGB code for red "FFFF0000"
red <- "FFFF0000"
# Or we can find out what that code is by starting from a cell that we know is
# red.
red_cell_format_id <-
xlsx_cells(path, sheets = "pivot-notes") %>%
dplyr::filter(row == 5, col == 2) %>%
pull(local_format_id)
red_cell_format_id## [1] 40## [1] "FFFF0000"Now we use behead_if(), filtering out cells with the format IDs of red or
italic cells.
cells <-
xlsx_cells(path, sheets = "pivot-notes") %>%
dplyr::filter(!is_blank) %>%
select(row, col, data_type, character, numeric, local_format_id) %>%
print()## # A tibble: 31 x 6
## row col data_type character numeric local_format_id
## <int> <int> <chr> <chr> <dbl> <int>
## 1 2 4 character Female NA 18
## 2 2 6 character Male NA 18
## 3 2 7 character 0 = absent NA 39
## 4 3 4 character Matilda NA 20
## 5 3 5 character Olivia NA 21
## 6 3 6 character Nicholas NA 20
## 7 3 7 character Paul NA 21
## 8 4 2 character Humanities NA 18
## 9 4 3 character Classics NA 19
## 10 4 4 numeric <NA> 1 33
## # … with 21 more rowscells %>%
behead_if(!italic[local_format_id], # not italic
direction = "up-left",
name = "sex") %>%
dplyr::filter(row != min(row)) %>% # discard non-header cells
behead("up", "name") %>%
behead_if(formats$local$font$color$rgb[local_format_id] != red, # not red
direction = "left-up",
name = "field") %>%
dplyr::filter(col != min(col)) %>% # discard non-headere cells
behead("left", "subject") %>%
select(sex, name, field, subject, score = numeric)## # A tibble: 16 x 5
## sex name field subject score
## <chr> <chr> <chr> <chr> <dbl>
## 1 Male Nicholas Humanities Classics 3
## 2 Male Paul Humanities Classics 0
## 3 Male Nicholas Humanities History 5
## 4 Male Paul Humanities History 1
## 5 Female Matilda Humanities Classics 1
## 6 Female Olivia Humanities Classics 2
## 7 Female Matilda Humanities History 3
## 8 Female Olivia Humanities History 4
## 9 Male Nicholas Performance Music 9
## 10 Male Paul Performance Music 2
## 11 Male Nicholas Performance Drama 12
## 12 Male Paul Performance Drama 3
## 13 Female Matilda Performance Music 5
## 14 Female Olivia Performance Music 6
## 15 Female Matilda Performance Drama 7
## 16 Female Olivia Performance Drama 83.1.5 Mixed levels of headers in the same row/column, distinguished by formatting
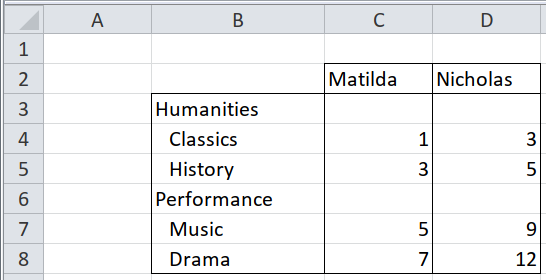
Normally different levels of headers are in different rows, or different columns, like Two clear rows of text column headers, left-aligned. But sometimes they coexist in the same row or column, and are distinguishable by formatting, e.g. by indentation, or bold for the top level, italic for the mid level, and plain for the lowest level.
In this example, there is a single column of row headers, where the levels are shown by different amounts of indentation. The indentation is done by formatting, rather than by leading spaces or tabs.
path <- system.file("extdata", "worked-examples.xlsx", package = "unpivotr")
formats <- xlsx_formats(path)
formats$local$alignment$indent## [1] 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0
## [46] 1 0 0 0 0 0 0 0 0 0 0 0 0 0We can use the indentation with behead_if() to make two passes over the column
of row headers, first for the unindented headers, then for the indented headers.
cells <-
xlsx_cells(path, sheets = "pivot-hierarchy") %>%
dplyr::filter(!is_blank) %>%
select(row, col, data_type, character, numeric, local_format_id) %>%
print()## # A tibble: 16 x 6
## row col data_type character numeric local_format_id
## <int> <int> <chr> <chr> <dbl> <int>
## 1 2 3 character Matilda NA 18
## 2 2 4 character Nicholas NA 42
## 3 3 2 character Humanities NA 18
## 4 4 2 character Classics NA 44
## 5 4 3 numeric <NA> 1 20
## 6 4 4 numeric <NA> 3 45
## 7 5 2 character History NA 44
## 8 5 3 numeric <NA> 3 20
## 9 5 4 numeric <NA> 5 45
## 10 6 2 character Performance NA 20
## 11 7 2 character Music NA 44
## 12 7 3 numeric <NA> 5 20
## 13 7 4 numeric <NA> 9 45
## 14 8 2 character Drama NA 46
## 15 8 3 numeric <NA> 7 24
## 16 8 4 numeric <NA> 12 47cells %>%
behead_if(formats$local$alignment$indent[local_format_id] == 0,
direction = "left-up",
name = "field") %>%
behead("left", "subject") %>%
behead("up", "name") %>%
select(field, subject, name, score = numeric)## # A tibble: 8 x 4
## field subject name score
## <chr> <chr> <chr> <dbl>
## 1 Humanities Classics Matilda 1
## 2 Humanities Classics Nicholas 3
## 3 Humanities History Matilda 3
## 4 Humanities History Nicholas 5
## 5 Performance Music Matilda 5
## 6 Performance Music Nicholas 9
## 7 Performance Drama Matilda 7
## 8 Performance Drama Nicholas 12